


Imagine you've read fifty books over the past few years and highlighted passages in all of them. Now you have a question: "What do my books say about how people resist change?" The answer might live in a psychology textbook, a business case study, a historical account, and a novel — scattered across thousands of highlights.
This is the retrieval problem — the central challenge for anyone building AI systems that work with large text collections. In my case, that's a reader's personal library of Kindle highlights organized by book and chapter structure in DeepRead. Simply dumping everything into a big context window doesn't work — models degrade as context grows, losing track of information and letting heavily-highlighted books drown out sparser ones. (I explored this in my previous article on teaching an LLM to navigate my library.)
So how do you help the AI find what matters without overwhelming it? There are four fundamentally different strategies, each implying a different philosophy of how to "read." The easiest way to understand them is to imagine four very different humans tackling your library.
Imagine someone who takes every book in your library, tears out the highlighted passages, writes each one on an index card, and tosses all the cards into a giant box. When you ask a question, they rummage through the box and hand you the cards that seem most relevant.
This is essentially what standard Retrieval-Augmented Generation (RAG) does. It breaks your highlights into chunks, converts each chunk into a numerical representation of its meaning (called an embedding), and stores them in a database. When you ask a question, your question gets the same treatment — converted into numbers — and the system finds the chunks whose numbers are mathematically closest to yours.
The technical term for this is semantic search, and its great strength is that it works by meaning, not keywords. When I search my library for "free will," my RAG setup doesn't just find highlights containing those exact words. It finds passages about choice, determinism, and moral responsibility. It even surfaces German-language Dostoevsky quotes about human agency — passages that share none of the English words but express the same ideas. This is what makes it the default retrieval approach in tools like Claude's Projects, ChatGPT's file search, and most AI-powered knowledge systems today.
But think about our index card maker. They've destroyed the book. They don't know that the passage on card #47 was a counterargument the author raised only to refute it three chapters later. They don't know that the quote on card #112 is from the introduction, where the author was deliberately oversimplifying before adding nuance. They've kept the words but thrown away the structure — and structure is where much of the meaning lives. There's also density bias: if one book has 300 highlights and another has 15, the system will almost always surface the larger collection, even if the smaller one contains the deeper insight.
Frameworks like LlamaIndex and LangChain make it straightforward to build such a system — they handle chunking, embedding, and retrieval. But the underlying limitation remains: you're searching through fragments that lack context.
Now imagine a different reader. Before answering any question, they first go through your entire library and map out every person, concept, event, and idea mentioned — and, crucially, how these elements relate to each other. They build a giant web: "Author A argues X, which contradicts Author B's claim Y, which is supported by the case study in Book C." Only then do they answer your question — by walking through this web of connections.
This is GraphRAG, an approach developed notably by Microsoft. It constructs a knowledge graph from your documents: nodes represent entities and concepts, edges represent relationships between them. When you ask a question, the system doesn't just find relevant text — it traverses the graph to find chains of reasoning that connect different pieces of information.
Where this shines is multi-hop reasoning — questions where the answer requires connecting information from different places that no single chunk contains. "How do three different authors in my library approach the question of habits?" A standard RAG system would retrieve chunks from each author separately. A GraphRAG system could trace the conceptual connections and contradictions between them, because it has already mapped those relationships.
Now think about our relationship mapper as a human reader. They're the person who, before discussing any book, first spends weeks creating elaborate concept maps and cross-reference tables. For certain questions — especially broad, thematic ones — it produces answers no other approach can match.
But it's expensive. Building the knowledge graph requires processing every document with an LLM, extracting entities and relationships, and running clustering algorithms. For a personal library of fifty books, this might mean hours of processing and significant API costs — and the graph needs rebuilding whenever you add new books. For highly relational domains like legal compliance or medical research, this investment pays off. For a reader who wants to find relevant highlights across their library, it can feel like bringing an industrial crane to hang a picture frame.
Now imagine a researcher who doesn't read your entire library upfront and doesn't create index cards. Instead, they sit at a desk with all fifty books stacked beside them. When you ask a question, they think about it, pick up a book that seems promising, flip to the table of contents, scan a few chapters, read the relevant passages, then set that book aside and pick up another. They might go back to a previous book when something in the second one triggers a connection. They decide, on the fly, how deep to go.
This is the Recursive Language Model (RLM) approach, introduced in a recent paper by Zhang, Kraska, and Khattab at MIT. Instead of stuffing all your text into the context window or pre-chunking it into a database, the model treats the text as an environment it can programmatically navigate. It loads the content as a variable in a Python environment and writes code to search, slice, and recursively call itself on relevant portions.
The results are striking. In tests with GPT-5, the base model scored 0% on multi-document research tasks that exceeded its context window. The same model with the RLM approach scored 91%. What's remarkable is that the models developed their own search strategies — using regex to filter content, breaking tasks into recursive sub-calls, even verifying answers by querying themselves again — all without any special training.
Coming back to the human analogy: this is the reader who trusts their own judgment about where to look. They don't need a pre-built index or a relationship map. They navigate by intuition and skill, going deeper where it matters and skimming where it doesn't. On average, they read far less text than the brute-force approach while finding better answers — though their path is unpredictable, and sometimes they'll recurse into dead ends.
For a personal library of book highlights, this approach has a natural appeal: the AI browses your books the way you might browse a bookshelf. The open-source RLM library already supports major AI providers, and researchers at Prime Intellect are calling it a likely paradigm shift for how models handle large contexts.
Finally, imagine a scholar. They don't tear the books apart, and they don't just skim them on demand. They read each book carefully — chapter by chapter — and take structured notes. For each chapter, they note the main question being asked, the central claim, the key evidence. They understand that Chapter 3 sets up a counterargument that Chapter 5 will refute. They know that the anecdote in the introduction isn't the author's main point — it's a hook. When they're done with a book, they have a layered summary: the whole book in a sentence, each part in a paragraph, each chapter in a few bullet points — all nested within the book's own structure.
When you ask this scholar a question, they don't search through index cards. They think: "Which books address this? What chapters? Let me check my notes on the argument structure." They retrieve not fragments but contextual understanding.
This is the approach I've been developing in my experiments with Claude Code and Kindle highlights. At its core is what I call the nucleus-satellite model, borrowed from Rhetorical Structure Theory (RST) — a framework from linguistics that describes how texts are organized into core ideas (nuclei) and supporting material (satellites). For nonfiction, a nucleus is a question-claim pair: "Why do habits stick?" → "Because small changes compound." Satellites are the evidence, examples, and context that support this claim.
The key insight is that books have inherent hierarchical structure — and preserving that structure during indexing gives the AI something no chunk-based system can provide: understanding of how arguments are built.
What excited me when researching this article is discovering that I'm not alone. A December 2025 paper called BookRAG by Wang et al. introduces almost exactly this concept: a "BookIndex" that extracts hierarchical trees from books and uses agent-based querying inspired by Information Foraging Theory — significantly outperforming flat RAG approaches. A February 2026 paper called DeepRead (coincidentally sharing a name with our app) proposes a structure-aware reasoning agent that preserves heading hierarchies and reads entire sections once it finds a structural anchor.

And the theoretical foundation goes back further — RST-based indexing for information retrieval has been studied since the early 2000s, with researchers building systems that used rhetorical relations to improve search relevance.
The careful scholar's method is the most labor-intensive upfront. Each book requires a deliberate reading pass where the AI processes content chapter by chapter, building layered summaries — what I've described as Nested Summarization in a previous article. But once done, retrieval becomes deeply informed. The system doesn't just know what words appear in your highlights — it knows what role each passage plays in the author's argument. This is where DeepRead's exports become particularly valuable: they preserve highlights nested within the book's chapter structure, providing exactly the hierarchical input this approach requires.
Each approach has a natural home.
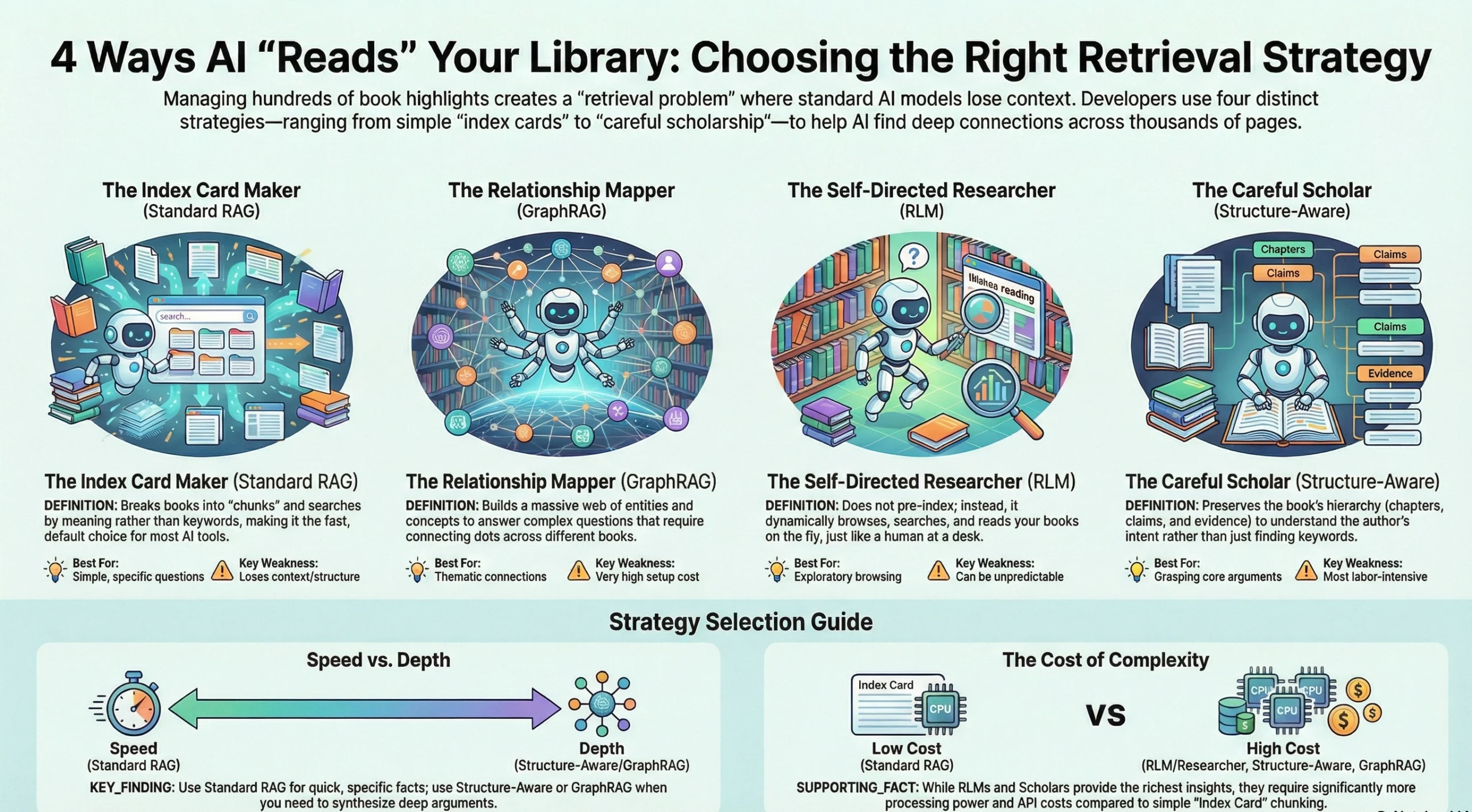
The index card maker (standard RAG) is your best starting point for specific questions where a single relevant chunk usually contains the answer. It's fast, affordable, and well-supported. It struggles when your question requires synthesis across sources or when argument context matters.
The relationship mapper (GraphRAG) earns its keep when documents are densely interconnected and questions demand multi-hop reasoning — legal codebases, research corpora, compliance documents. For most personal libraries, the setup cost outweighs the benefit, though this may change as tooling matures.
The self-directed researcher (RLMs) is the most exciting newcomer — flexible, requiring no upfront indexing, and scaling naturally because it reads only what it needs. Ideal for exploratory questions where you don't know which books will be relevant.
The careful scholar (structure-aware indexing) is the right choice when you want the AI to truly understand your books — not just find relevant words, but grasp how arguments are constructed. It's the most expensive approach per book, but it creates the richest index — one that supports not just retrieval but genuine knowledge synthesis across your entire reading history.
In practice, the most powerful system will combine these. Use semantic search as the fast first filter. Let the AI navigate recursively when it needs to explore broadly. And fall back on structure-aware indexing for the books you've invested the most in — where understanding the argument matters as much as finding the right quote.
The deeper lesson: the way we help AI find knowledge in our books mirrors the way we ourselves search for knowledge. The tools are different. The reading strategies are timeless.