


This is a genuinely new distribution pattern. You don't share the system — you share the idea of the system. Your agent adapts it to your tools, your domain, your needs. The concept becomes the primitive. The code is just one possible instantiation.
Karpathy built his system for research — collecting articles, papers, repos, and datasets from across the web. Most of the reactions came from developers and knowledge workers thinking about how to organize the notes, bookmarks, and web clippings they accumulate. That's a valid use case. But it's not where this idea has the most potential.
Readers who collect highlights and annotations are better positioned for a living knowledge base than notetakers — because they've already done the hard work. A notetaker copies fragments from the internet and drops them into folders. A reader has spent hours engaged in sustained, structured arguments. They've followed an author's reasoning from premise to conclusion. They've marked the passages that resonated, challenged their thinking, or offered something genuinely new. That's not raw material — that's partially processed knowledge, already filtered by attention and judgment.
The problem is that this knowledge is locked in individual books. Your highlights from a negotiation book don't talk to your highlights from a psychology book, even when they address the same underlying question. Each book is a vertical silo — rich inside, disconnected outside. What's missing is a system that brings your reading to life: an intellectual sparring partner that knows what you've read, understands what you're working on, and surfaces the right insight at the right moment — for the decision you're making, the discussion you're preparing, the problem you're trying to solve.
That system is what we're calling a reading intelligence layer. Not a note-taking app. Not a search engine over your highlights. A knowledge architecture that does the heavy lifting of structuring, connecting, and synthesizing — while you explore, react, and direct. The system produces. You curate.
Building it requires two things: a vertical structure that captures each book's logic and argumentation, and a horizontal layer that finds the connections across books that actually matter to you. Let's look at both.
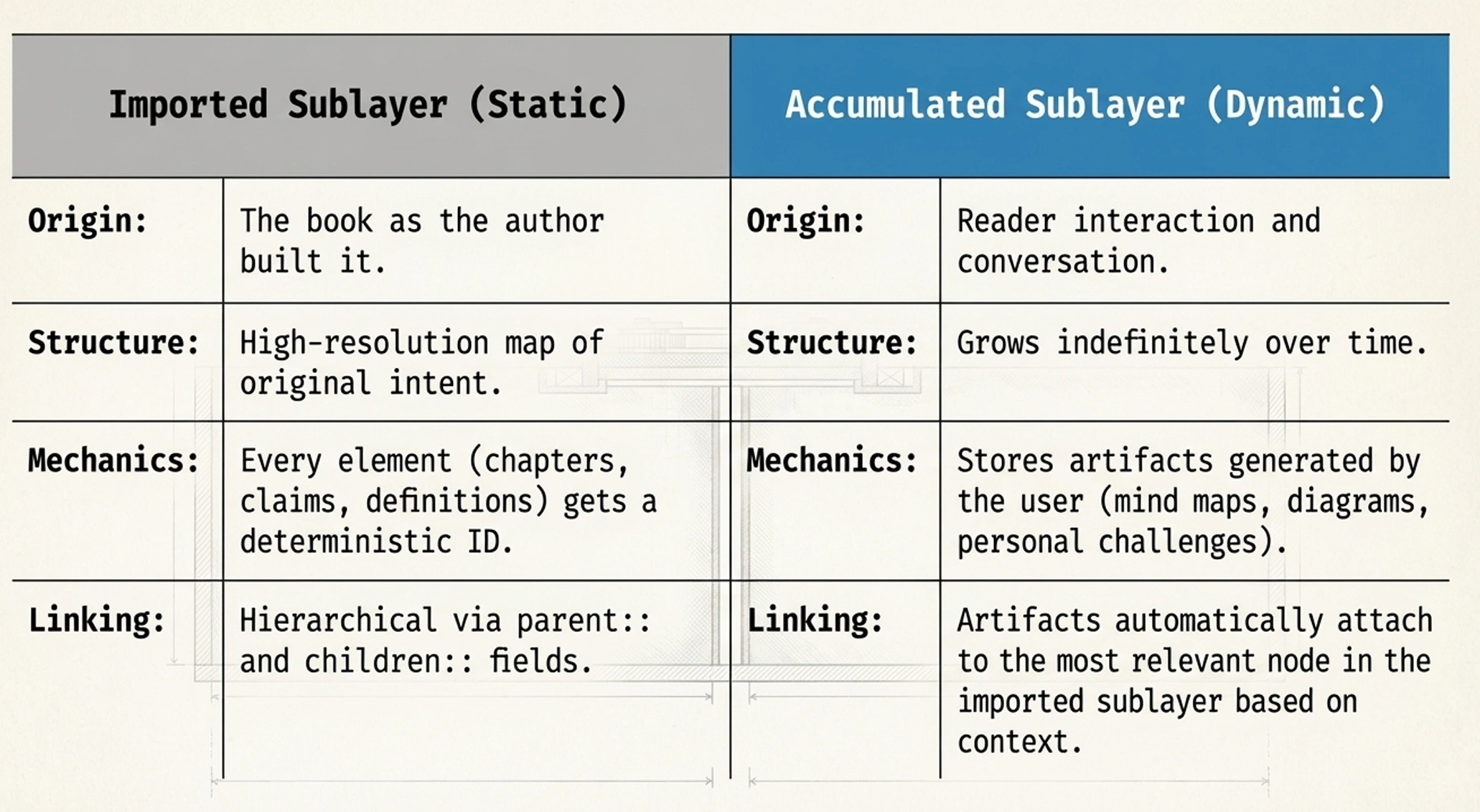
The starting point is what you already have: the books you've read and the highlights you've taken. These could be Kindle highlights, annotations in a PDF, or notes from a physical book transferred into digital form. This raw material is the foundation — immutable, never modified by the system, always the source of truth.
But raw highlights alone aren't enough for an LLM to work with effectively. A list of 200 disconnected passages from a 300-page book doesn't tell the system how those ideas relate to each other, which claims are central and which are supporting evidence, or how the author's argument builds from chapter to chapter. The structure matters as much as the content.
This is where what we call Recompose comes in — a processing engine inspired by Rhetorical Structure Theory, which analyzes how ideas in a text relate to each other hierarchically. The LLM is instructed to read the source material the way a human reader would: chapter by chapter, taking notes along the way. It identifies the main question each chapter tries to answer, the central claim, the key arguments and evidence supporting that claim, the important analogies and counterpoints, and the most significant quotes. Then it synthesizes these notes upward — chapter summaries inform part summaries, which inform the book-level summary.
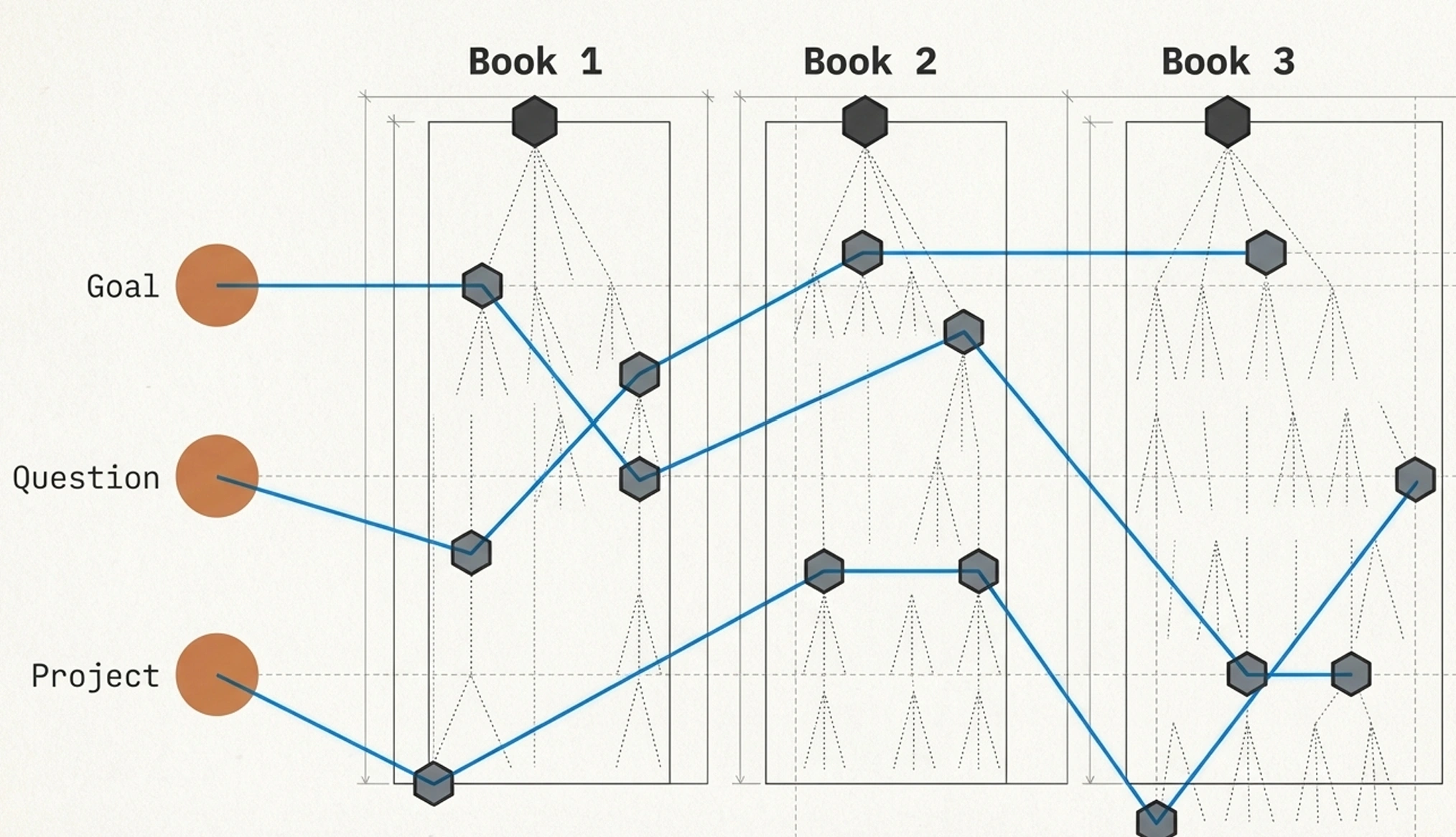
The result is a hierarchical map of the book's argumentation — not a flat list of highlights, but a structure that preserves how the author built their case. At the core are what we call nuclei: question-and-claim pairs that represent the book's fundamental idea units. Around each nucleus orbit satellites: the supporting material that gives the claim its weight — key terms, arguments, evidence, analogies, counterpoints, and quotes.
Every element links to its parent and children. A quote links to the satellite it supports. A satellite links to its nucleus. A nucleus links to its chapter. The chapter links to the book. This means the LLM can navigate from any single highlight up to the book's overall argument, or drill down from a high-level claim to the specific evidence supporting it.
For nonfiction, this structure follows the logic of argumentation: questions, claims, evidence, and the relationships between them. For fiction, the same architectural principle applies but with different elements — characters, plot threads, themes, and narrative arcs replace claims and evidence, while preserving the hierarchical relationships that make the story coherent.
Each book processed this way becomes a vertical column in the knowledge base — self-contained, richly structured, and ready to be connected to other columns.
This is where Karpathy's core insight — a knowledge system that compounds over time — meets a problem specific to readers. With vertical columns in place, the system could start cross-referencing everything to everything. Two books mention "feedback loops"? Connect them. Three authors discuss motivation? Create a shared page. The LLM is perfectly capable of doing this.
The problem is that this approach generates an almost infinite number of possible connections, most of which are irrelevant to you specifically. Two books both mentioning "leadership" doesn't mean the connection is worth surfacing — not unless leadership is something you're actively thinking about, working on, or trying to understand better.
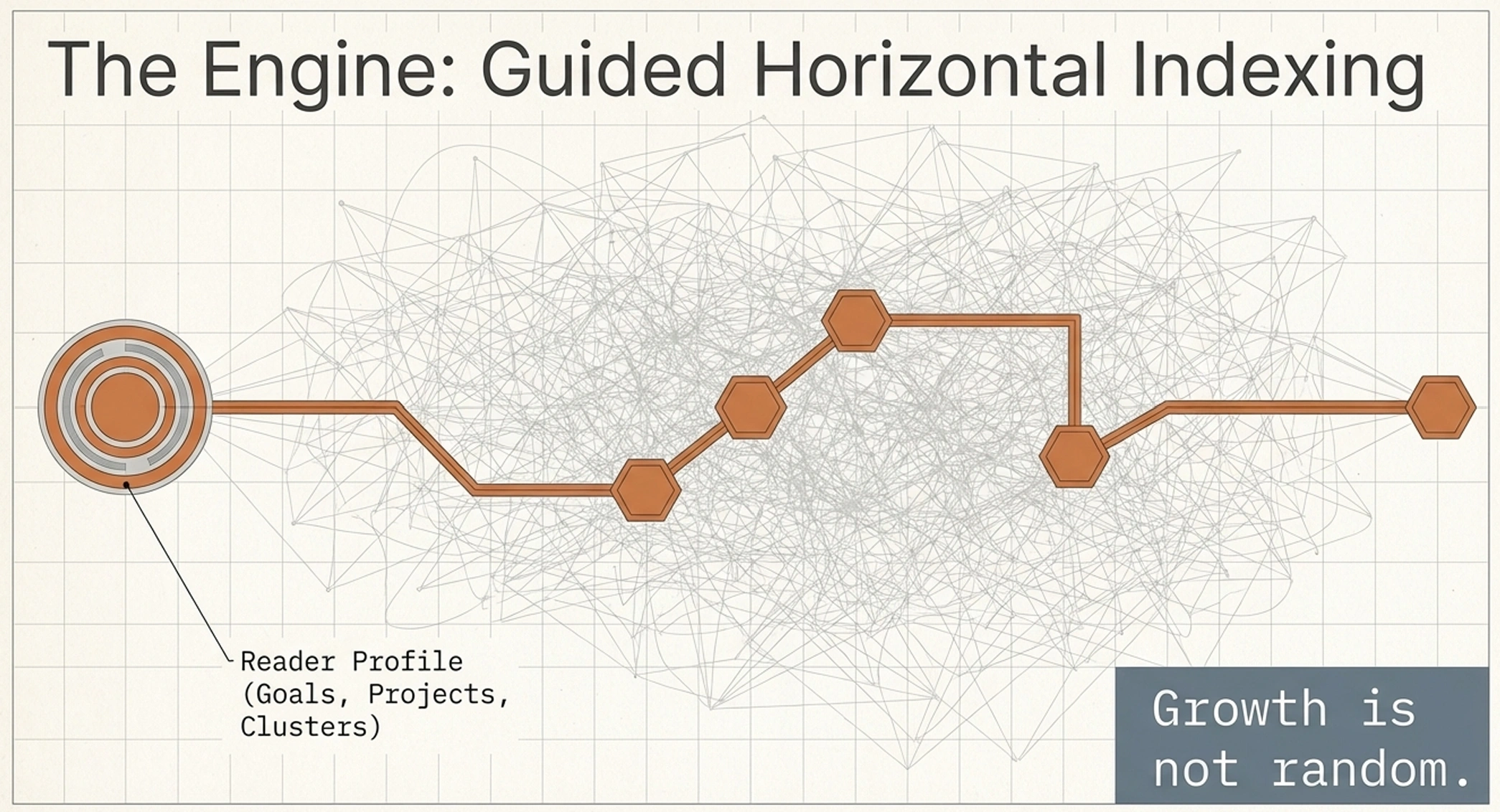
The horizontal layer is built with perspective — guided not by what's theoretically connectable, but by what the reader is actually trying to learn, solve, or achieve. The system actively tries to understand you: your reading goals, the questions you keep coming back to, the projects you're working on, the domains where you're trying to build expertise. Sometimes it learns this through direct questions. Most of the time, it picks it up from how you interact — what you ask about, what you explore, what you skip.
This reader profile becomes the lens through which cross-book connections are evaluated. If you're reading about negotiation because you're preparing for a difficult conversation, the system knows to look for connections between your books on psychology, decision-making, and communication — and to surface them with that specific context.
To prevent the system from growing uncontrollably, every horizontal connection follows a three-stage lifecycle:

The system is liberal with candidates and conservative with full pages. This keeps the knowledge base rich with possibilities but focused on what's genuinely useful.
What makes this architecture more than a static index is the set of feedback loops baked into every layer. Karpathy described three core operations for his system: ingest, query, and lint. For a reading intelligence layer, these translate into mechanisms that make every interaction count.
Conversation mining is perhaps the most important one. After every conversation you have with the system — whether you're exploring a single book, asking a cross-library question, or working through a problem — the entire exchange is scanned for extractable value. Did you connect ideas from different books? That becomes a synthesis candidate. Did you state a position or conclusion? That gets filed as a reader note on the relevant page. Did you ask a question that spans your library? That becomes a question page. Did you reveal something about your goals or interests? Your reader profile gets updated.
Every conversation makes the system more powerful — not because it remembers chat history, but because it mines each interaction for knowledge that gets woven into the permanent structure.
Cross-indexing runs whenever a new book enters the system. The LLM reads the new book's structure, then systematically compares it against the existing library — looking for semantic overlaps in key concepts, contradictions or reinforcements of core claims, and questions that connect to existing question pages. New concept candidates, synthesis candidates, and cluster assignments emerge automatically.
Lint passes are the system's health checks — directly inspired by Karpathy's approach. The LLM scans the entire knowledge base for structural problems: broken links, orphan candidates that have gone stale, thin pages that should be demoted or enriched, clusters with books but no synthesis pages, and books that were ingested but never explored. Lint also looks for promotion opportunities — candidates that have quietly crossed the threshold through new arrivals or conversations.
The following table maps Karpathy's original elements to how they manifest in a reader's knowledge system:
| Karpathy's Element | Reading Intelligence Layer |
|---|---|
| Raw sources (articles, papers, repos) | Book texts, Kindle highlights, annotations |
| Wiki (LLM-compiled, interlinked pages) | Vertical layer (RST-structured book vaults) + horizontal layer (cross-book concepts, syntheses, questions) |
| Schema (instructions for the LLM) | Recompose engine, reader profile, lifecycle rules (candidate → drafted → validated) |
| Ingest (process new source) | Book decomposition via Recompose + automatic cross-indexing against existing library |
| Query (ask questions) | Conversations guided by reader profile and goals, with outputs filed back into the system |
| Lint (health checks) | Structural hygiene, content gap detection, candidate pruning, promotion opportunities |
| Index (navigational catalog) | Master index + per-book registries + horizontal layer index |
| Log (chronological activity record) | Activity log with token counts, feeding into a reader-facing start page |
| Backlinks and cross-references | Reader-profile-guided connections: only cross-references relevant to your goals, questions, and projects |
We're currently implementing this architecture into DeepRead PRO. The vertical layer — Recompose and the structured book vaults — is already working. The horizontal layer, the reader profile, the conversation mining pipeline, and the lint passes are what we're building now.
The goal is a system where your library doesn't just sit there waiting to be searched. It works while you're away — finding new connections as you add books, updating syntheses when new evidence arrives, surfacing the right insight when you start your next session. A knowledge system that grows more valuable with every book you read and every conversation you have.
If you've been experimenting with LLM-powered knowledge systems on your own — whether with Obsidian and Claude Code, or with tools like NotebookLM — we'd love to hear what you've learned. We're building these features in the open and looking for readers who want to shape how this works. You can join our co-development community here — we're looking forward to your ideas, your experiences, and your feedback.
If you want to go deeper on the individual building blocks, you can read about how we structure books using chapter hierarchy and rhetorical structure, how cross-library connections work in practice, and how we use Claude Code to bring our reading to life.